This Wikipedia Article Doesn't Exist
How I made Tensorpedia (adventures in machine learning and server architecture)
project
Have you ever wondered how an AI would interpret the world? How it would see the universe? How it would parse knowledge? How it would dream? Meet Tensorpedia! - The latest project I've created. It answers... none of the previous questions, but I think what I've created is interesting nonetheless.
Click here to check it out!
Click here to jump to the examples!
Background
An infinite number of monkeys something something Shakespeare. Yeah, that sounds about right.
Émile Borel, 1913
It's no secret that the Artificial Intelligence and Machine Learning fields have been exploding in recent years. Sure, they can trace their roots all the way back to the 1950's. However, we're in the midst of a gigantic exponential growth in the field. It's a combination of people realizing the potential that these models can have and the absolute raw parallel computing power that we have available nowadays. In any case, I think the whole thing is just neat.
A while back on the Internet, there was an explosion of AI-generated content. We finally reached a point where the average Joe can make a request to a neural network and have it generate something that "doesn't exist" on-demand. From making your favorite characters say things, to generating realistic looking people, and having an AI finish your sentences, I was completely enamored with the stuff. Though, I never thought that I had the skill set in order to make anything as high quality as the aforementioned sites... Until the beginning of this December.
I was looking for something to do between my fall 2021 and as-of-yet-not-begun spring 2022 semesters. I came up with an idea for another project (that I won't divest too much information on) that involved using the Wikipedia API. I later came across Wikipedia's vital articles lists, articles which Wikipedia believes talk about the most important topics in their English Encyclopedia. Furthermore, I realized that I could fairly easily scrape the titles of these articles via their incredible petscan tool.
It's like the idea for Tensorpedia was staring me straight in the face. I had input in the form of Wikipedia titles, output in the form of Wikipedia articles, and could get a whole lot of both from the API. This task was ripe for an AI-based project. And so, I set to work creating Tensorpedia.
My Web Design Philosophy
My philosophy in web design (heavily inspired by the creator of Svelte, Rich Harris) is that most websites nowadays really don't need big fancy frameworks. While things like React, Vue and Angular are all well and good, all most websites need are sprinkles of reactivity interspersed within mostly static content. For instance, this website you're looking at is hosted entirely on GitHub pages built using a nifty tool called Eleventy.
This philosophy of reducing the amount of JavaScript bloat within the sites I design has three major benefits: The first and more altruistic result is that my website is reasonably fast and light. If there's nothing to weigh it down, there's nothing to weigh it down. It's a tautology, sure, but the truth. The second benefit is that I don't have to worry about web security this way. If my GitHub Pages site gets hacked, then that's GitHub's problem. And something tells me that GitHub dedicates many more man-hours making sure they don't get hacked than I ever could to my site. The final, and pretty selfish reason, is that it's plain cheaper to host a static site. I'm definitely not made of money, and hosting a custom server requires some of it.
All of this was the motivation behind my first (read: failed) idea.
One way to generate text when it comes to neural networks is to use what's called a recurrent neural network. Without getting too much into the weeds, it's a pretty powerful type of neural network. Most importantly to me though is that the neural networks are small.
In fact, according to the library I was using, textgenrnn, the model weighs in at around only 2 MB. Great! I can send over the whole program in a website, and have everything computed on the client-side! No extra server costs needed! I left my computer overnight to churn away at the data I had gathered.
The next day, I excitedly thought of what I could generate an article about. Toasters, how about toasters! This is what I saw a minute later after asking it about this prompt:
Toaster: Bank is also called nationalism and despression of the equation and the Achaemenid Empire. The Allied independent in the world. Protective also produces a social science of a process that continue to distinguogy from the professional law of natural and polar is the stone is a member of the primary science of the world's sexual or international processes of the present day...
Never mind the fact that "despression" and "distinguogy" aren't real words; it said nothing about toasters or anything remotely toaster-adjacent! Unfortunately, LSTMs don't have that much power when it comes to generating coherent pieces of text on a specific topic. This idea was a bust. However, I did know of another type of neural network that generates text on-topic fairly well.
Transformer Neural Networks
Transformers are another type of neural network that can be used to generate text. They're even more complicated than the basic LSTMs I was trying to use, but the results that they generate are incredible. I first became aware of them when GPT-2 came out and flipped the world of AI on its head. OpenAI released pre-trained versions of GPT-2 that anybody can use and fine-tune to their specific need.
The only problem? The lightest version of GPT-2 has 124 million parameters, expanding to around five hundred megabytes unzipped. Imagine asking people to download the equivalent of 200 DOOMs or three and a half Half-lives. No Bueno.
So I finally had to just bite the bullet and finally buy myself a server. No way I was going to host this thing on my property - there are just too many security risks. Instead, staring at my bank account, I wound up purchasing a six-dollar-a-month single-core DigitalOcean Droplet. It's most definitely not the fastest thing in the world. In fact, it doesn't even have a GPU, something that would make AI generation much faster. But it's cheap and has high uptime, and that's all that matters to me right now.
If Tensorpedia gets popular enough, maybe I'll take a look at Linode GPU instances or something.
The "Guts" of the Project

Image found via Museo and the Rijksmuseum.
I'll spare you the stressful details of trying to set up HTTPS with the default configuration of Nginx on the server. I'll not mention the confusion that Python versioning conflicts on Ubuntu 20.04 caused me. I'll even keep mum about the fact that the paid version of Google Colab kept resetting all my training progress by logging me out four times.
No, I won't mention any of that. Instead, I'll describe what the whole system ended up looking like at the end.
The front end is quite simple. It's just some CSS, HTML, and vanilla JS. I didn't see the need for Tensorpedia to include a big framework like React or Vue for something that's, at its core, not terribly complicated. The only library I do depend on is Socket.io. When the user opens the page, the browser creates a Websocket connection to the API server. Then, when they "navigate" to a new page, the query gets pushed to the browser's history, and a request is made over the socket.
The server is also quite simple. It has three main parts: the aitextgen Python program, the Redis cache, and the node.js server. When the server recieves a request over a client's socket, it first checks whether the client wants to regenerate the page or not. If they don't, it checks the Redis cache to see if the page has been generated already. If they want a new page or it's not in the cache, the request is queued over to the python program via UNIX sockets. The result is then stored in the cache, and sent back over to the user.
Note: this does create a bottleneck at the Python program, but as my server is vastly underpowered, it kinda needs to be that way. Tensorflow takes an incredible amount of CPU resources, and processing the requests one at a time alleviates that stress.
The Python program was trained using the scraped Wikipedia API data utilizing the aitextgen package on Google Colab. I then transferred the trained model to the server. The library provided a significant speedup over just using raw GPT-2 generation tools. Performance quite matters when you only have one core. Hat's off to minimaxir for creating such an easy-to-use tool.
It all seems simple, and in retrospect it really is. However, the devil is in the details.
Examples of Generated Articles
Finally, let's check out some examples of what Tensorpedia can do! If you skipped to this section, I see you. If you're on a mobile device, I'd recommend opening these images in a new tab.
First up, let's generate an article on Toasters!

You can really see the bias of the ten-thousand vital articles come through. The vital articles contain big bombastic events in history, incredibly influential figures, or abstract ideas like love. Toasters just don't fit into those categories. Overall, B+ effort by Tensorpedia.
However, as a side effect, Tensorpedia will tend to think everyone is a super important person, every place is a historical place, and every object has a world-changing idea behind it. Let's look at the most average guy in history, Joe Shmoe.

New Zealanders, is Joe Shmoe your best-kept secret to your Olympic swimming success? Please let me know. Additionally, though I can't show just one example, the bias of time periods tends to be almost exclusively during the 19th and 20th centuries. I thought I'd just share that as an interesting note of where our bias of "what's important" lies.
Repetition is an issue in any transformer neural network. You'll notice that certain phrases are repeated once or twice if you browse Tensorpedia enough. But you know what area Tensorpedia had trouble with the most in this regard? Russian. For example:

Now I don't speak Russian, but I'm pretty sure that's nonsense. Luckily, aitextgen includes a parameter to discourage repetition. After enabling it, this is what we get:
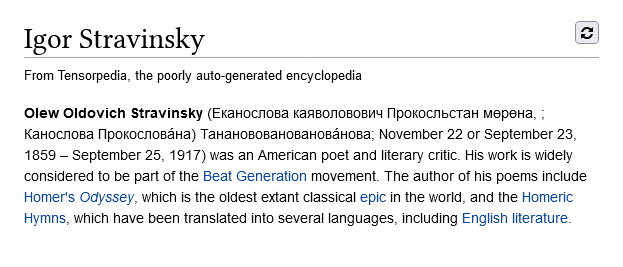
Just a little bit better, don't you think?
Next, I want to share what I think is the coolest article I came across while building Tensorpedia. I put in the prompt "Awesomium" and it gave me this:
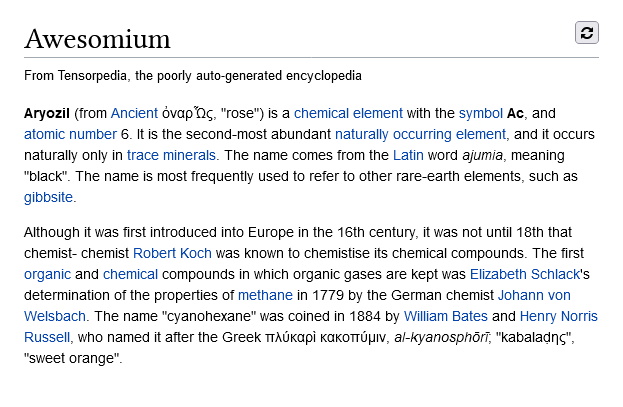
All just from the title "Awesomium," it deduced that it was probably an element, its atomic symbol, number, etymology, and history. Pretty crazy!
The final three examples I'll give to you in rapid-fire mode. The first example shows that Tensorpedia can link to "interesting" (yet plausible!) words.

The next one shows that Tensorpedia has a rudimentary understanding of history, generating dates from the appropriate period for Rome.

Finally, even though Tensorpedia may not know about pop culture, it can be scarily accurate about the mathematical objects pop culture references.
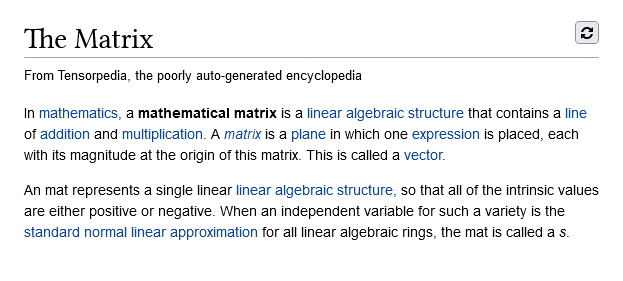
Future Improvements and Conclusion
All in all, I'm extremely pleased with how this project turned out. I wanted to get this project finished before the new year. Oh well, c'est la vie, I suppose.
That is not to say, however, I think there's no room for improvement.
For one, the neural network works, but it's painfully slow sometimes. I've had articles where it takes on the order of 2 minutes to generate. Far too long! There's not much I can do aside from buying more power on the server. One thing I have been looking at is potentially using Microsoft's ONNX runtime to speed it up, but that would require digging into the guts of aitextgen to do.
Another improvement is that I'm not quite used to event-driven programming yet. I utilized quite a bit of "async" and "await" in my code, but I'm sure there's a more clever and elegant way to accomplish what I want to do. Perhaps this could allow me to utilize Redis more effectively as well.
But, as I stated before, I'm quite happy with how Tensorpedia turned out.
Thank you for reading, and please enjoy Tensorpedia!